While most Windows developers know of Event Tracing for Windows (ETW) as a logging and tracing mechanism, many administrators have never heard of it. Simply put, ETW includes event logging and tracing capabilities provided by the operating system. Implemented in the kernel, it traces events in user mode applications, the operating system kernel and kernel-mode device drivers.
Event Tracing for Windows is used by a number of core OS components and some third-party applications to provide event logging and tracing. Although it required access to a checked build of Windows to gather ETW information when first released with Windows 2000, more recent versions provide built-in tools with normal (free) Windows builds.
Getting started with Event Tracing for Windows
When diagnosing and troubleshooting Windows Server issues, it seems there is never too much data. The admin is always looking for additional details on what is going on with various components to pinpoint the problem. As such, there are a number of tools like Process Monitor,Process Explorer, Performance Monitor (Perfmon) and Performance Analysis for Logs (PAL) that dig considerably deeper than the event log, but there are times when we need to dig even further down than that.
ETW allows additional instrumentation for gathering data that would not otherwise be available and has a number of advantages. For example:
-
it uses per-processor kernel buffers from a non-paged pool that are not impacted by application crashes or hangs
-
it uses very low CPU overhead
-
it’s available for x86, x64 and IA64 architectures
-
it can enable and disable tracing without rebooting or restarting applications
Event Tracing for Windows may seem like a great tool, but using it is another issue since there is no GUI or user guide. It also requires a few preliminary steps just to produce output that can be used for analysis.
In order to provide useful output you need a consumer. The consumer built in to Windows Server is Tracerpt.exe. As you can imagine, there are a number of flags for Tracerpt to provide specific output formats, so it’s important to become familiar with the Tracerpt and Logman utilities that are native in Windows Server 2003 and up, as well as Windows 7 and Vista.
It’s also important to understand the architecture for ETW. As you can see in Figure 1, the controllers are used to start and stop a tracing session. The tool used to do this in Windows Server 2003 and 2008 is Logman.exe.
Figure 1. The ETW architecture

Image credit: Microsoft Corp.
Windows Server 2003 also contains a handful of event providers that return specific events, including the following Active Directory-related providers:
- Active Directory: Core
- Active Directory: Kerberos
- Active Directory: SAM
- Active Directory: NetLogon
For instance, specifying Active Directory: Kerberos as a provider will only return Kerberos-specific events.
Event providers differ between Windows versions, however. For example, Windows Server 2003 has 22 providers, while Windows 2008 has 387. This gives more power to the trace and offers more granularities. Yet when it comes to LDAP traffic, the Active Directory: Core provider appears to give the same detail for either Windows version.
You can also combine event providers into a single trace. Since Kerberos authentication was involved in the example above, I used the Active Directory: Kerberos and the Active Directory: Core providers and applied the Logman option-pf, as shown in the following example:
Logman Create Trace CoreKerb –pf c:\etw\input.txt –o c:\etw\coreKerb
The –pf option reads an input text file (input.txt in this case). The format of the input file is shown in Figure 2.
Figure 2. Input text file format

Putting Event Tracing for Windows to work
The best way to explain ETW is with a case study. Recently, I was contacted by an engineer who needed information about how Active Directory was responding to an LDAP request for a Unix client authenticating against an AD domain controller. He used a Unix command to see the bind request/response on the Unix side and wanted to see similar output on the Windows side. The output looked something like this:
[23/Sep/2010:15:04:44 +0200] conn=31 fd=65 slot=65 connection from 10.50.20.173 to 10.50.12.119
[23/Sep/2010:15:04:44 +0200] conn=31 op=0 BIND dn="uid=dorsa,ou=people,o=Corp.net" method=128 version=3
[23/Sep/2010:15:04:44 +0200] conn=31 op=0 RESULT err=0 tag=97 nentries=0 etime=0 dn="uid=dorsa,ou=people,o=corp.net"
[23/Sep/2010:15:04:44 +0200] conn=31 op=1 SRCH base="ou=people,o=hp.com" scope=2 filter="(|(uid=dorsa)(cn=mdilln.dodgcty))" attrs=ALL
[23/Sep/2010:15:04:44 +0200] conn=31 op=1 RESULT err=0 tag=101 nentries=2 etime=0
[23/Sep/2010:15:04:44 +0200] conn=31 op=2 UNBIND
[23/Sep/2010:15:04:44 +0200] conn=31 op=2 fd=65 closed - U1
[23/Sep/2010:15:04:44 +0200] conn=29 op=-1 fd=64 closed error 11 (Resource temporarily unavailable) -
To work through the output, I used the NTDS Diagnostics registry key atHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Diagnostics and defined the LDAP Interface for a value of 5. It only provided the elapsed time of the operation and wasn’t close to the Unix output, so I decided to try Event Tracing for Windows. Since this was on Windows Server 2003, I used the Active Directory: Core provider, which gave LDAP details.
Below are the steps and commands I used to create an ETW trace and generate a log. The commands were used to dump LDAP data during authentication for the Unix engineer. I also created a C:\ETW directory to store all my data.
-
C:>Logman Query Providers — This command lists all available providers. Note that the provider we are interested in for LDAP information is the Active Directory: Core provider.
- Logman create trace “LDAP1” –p “Active Directory: core” –o c:\etw\LDAP1 LDAP1 — This is the name of the trace (we’ll see it when we look at the list of traces).
- -identifies identifies Active Directory: Core as the provider we want to use.
- -o specifies the path for the output (.etl) file as C:\etw\ldap1 . The output file will be saved as LDAP1_000001.etl. Note that when the trace runs a second time the output file will be named LDAP1_000002.etl, etc.
-
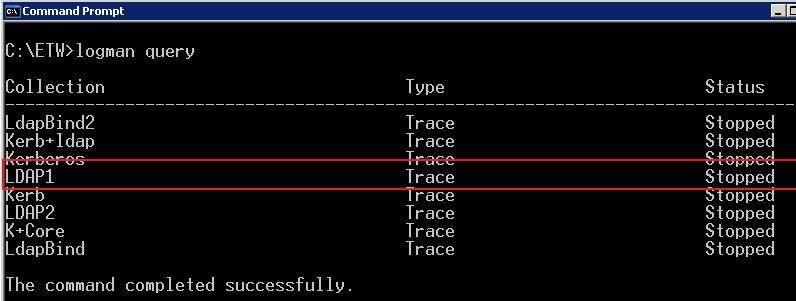
Once the trace is executed successfully with the Logman create trace command it can be seen in the queue with the command: C:>Logman Query. A sample output is shown in Figure 3. The LDAP1 trace is shown in the red box outline in the figure. Note that there are a number of traces I defined which can be reused simply by starting and stopping them.
Figure 3. ETW trace (click to enlarge)

-
The following command starts the trace:
Logman Start LDAP1
Issuing Logman Query at this point would show LDAP1 as “Running”.
-
Reproduction operations are then needed to reproduce the problem or situation you want to trace. In this case, I performed a logon and ran some LDIFDE commands to perform LDAP searches. Having these commands ready as soon as the trace starts will minimize the noise in the trace and make it easier to read.
-
Next, stop the trace: Logman Stop LDAP1
-
The C:\ETW directory now shows that the LDAP1 trace file LDAP1_000002.etl was created:
C:\ETW>dir ldap1*
Volume in drive C has no label.
Volume Serial Number is 309D-BA04
Directory of C:\ETW
10/13/2010 04:22 PM 1,015 ldap1
10/13/2010 04:20 PM 262,144 LDAP1_000001.etl
01/21/2011 02:12 AM 262,144 LDAP1_000002.etl
-
Because this is the second time running that trace, the file name was bumped to 000002.
Since the .etl log is unreadable we can use Tracerpt to give us some useful data. The command for this example would be:
TRACERPT LDAP1_000001.etl -o Ldap1.csv
-
- -of sets the file type (default CSV) (See online help for more formats.)
- -o represents the output file name default, which is dumpfile.csv and produces the most interesting dump of LDAP activity
- -Summary, -Report represents statistical data (not used in this example)
Opening the LDAP1.csv file in Excel (or Notepad) will allow a look at the data. Figure 4 shows part of my output file with the LDAP requests and responses highlighted. As you can see, the search and bind requests from the text are in column A, while in column B you can see the start and end of the requests, which can be paired up. Further to the right you can see the user data, the filter and scope of the LDAP request, and so on.
Figure 4. View of LDAP1.csv data (click to enlarge)

The exciting thing about Event Tracing for Windows is that the opportunities with providers seem endless. Providers for Group Policy, Kerberos, LDAP clients, Netlogon, FSRM, IIS and many more are all available in Windows Server 2008.
While I used to rely exclusively on event logs and similar log files, I can now go a level deeper with Event Tracing for Windows and get a lot more verbose data to help me solve whatever problem I’m troubleshooting. The commands to produce the traces and reports are very easy to use as well. Of course, you can find more command options and details online.
You can follow SearchWindowsServer.com on Twitter @WindowsTT.
ABOUT THE AUTHOR
Gary Olsen is a systems software engineer for Hewlett-Packard in Global Solutions Engineering. He authored Windows 2000: Active Directory Design and Deployment and co-authored Windows Server 2003 on HP ProLiant Servers. Gary is a Microsoft MVP for Directory Services and formerly for Windows File Systems.













You must be logged in to post a comment.